
Appian Low-code AI
This is a multi-year project to democratize AI and Machine Learning and enable Appian low-code developers without much data science knowledge to automate their applications using AI and ML. We are working towards our first release in early 2023.
I’m the sole designer working with 3 cross-functional teams that consist of product managers, ML engineers, developers, and quality engineers.
Design lead | 2021 - 2023 | Sketch, SAIL, user research

Problem and Goals
Why? What are we trying to solve?
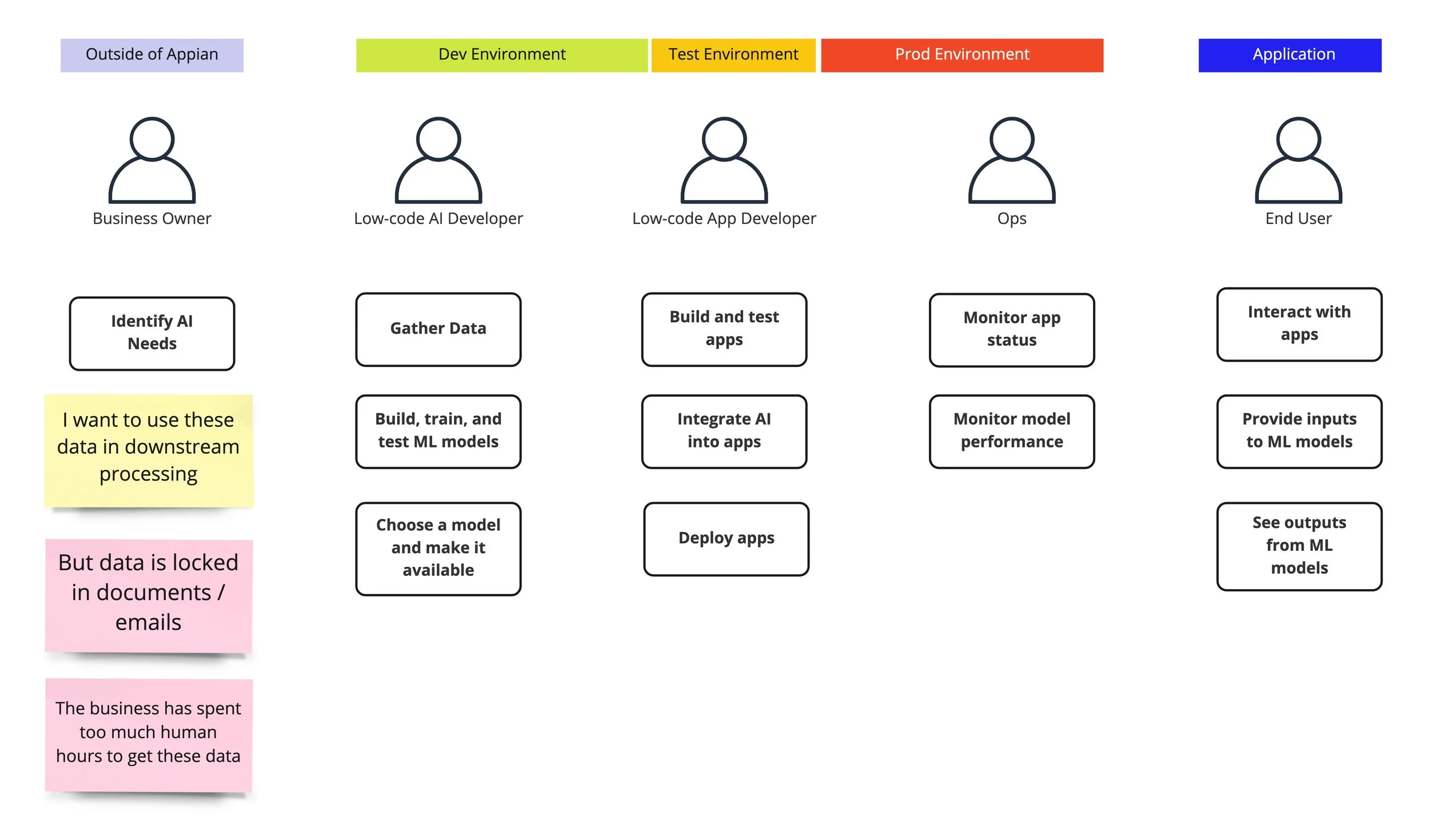
Customers use Appian low-code platform to automate their business process by reducing tedious and repetitive human manual tasks. The high entry barrier of AI and ML has been prevented our users from taking advantage of its full potential.
We also saw a low adoption rate of our Intelligent Document Processing offering. One of the main reasons is that the experience is disconnected from the core platform.
Our goal is to empower low-code developers to easily create, train, test, monitor, and use AI/ML in the Appian low-code platform to build automation applications.
Learning
To learn a new domain of AI and ML, I joined a cross-functional team and shadowed ML engineers to record their process of experimenting and developing ML models. I then summarized steps they took and envisioned a simplified low-code version for low-code developers.
Explore Persona and Make Hypotheses
Persona
To create a vision, there are a lot of questions we need to answer to narrow down to a direction. First, we made assumptions about our target persona.
Initially we assumed a development team would have a dedicated developer who only focused on ML model development, and other app developers would be consumers of the models. However, after working with Product Managers to analyze use cases, we realized it’s not a realistic assumption. We found that most of Appian project teams are small and every developers wear many hats, so we decided to focus on the typical low-code app developer persona who is familiar with the Appian platform, but doesn’t necessarily have much data science knowledge.
Open Questions
I listed out open questions to make sure the team made progress steadily to resolve them, including
- how to present AI/ML conceptually in the platform to create an integrated experience?
- what we’d like to focus on and prioritize to differentiate our product from others with powerful features out there?
- how to help developers discover AI and evaluate their use cases’ needs?
- what in-product guidance do we need to provide to ensure developers’ success?

Platform Integration
Discovery
Based on use case analysis, the team decided to first focus on the document space, especially document classification, because we have existing customers using Appian to solve document related problems.
After researching on many products out there, including Google Document AI, Microsoft AI Builder, AWS Sagemaker Canvas, ABBYY Vantage, Salesforce Einstein, and UiPath, I sketched out a few ideas of how to best integrate AI with the platform and discussed with PMs.
Iteration Process
I met with my team’s PMs at least once every week to brainstorm ideas and walk them through my current mockups to make sure the user flow reflects correct information. I also had weekly UX review sessions with my design director and a couple design peers for critiques. When there’s an agreed upon version of design, I walked through the design with engineers to gather their feedback from a technical perspective. I then recruited internal users to conduct user testing with prototypes.
Starting Point
Among all the ideas, the image above shows 4 of them.
Iteration 1: In their application overview, provide an option to add AI in their application and lead low-code developers to a separate AI Console.
Iteration 2: In the platform navigation bar, add a high-level “AI Tab” which is separate from the existing “Build Tab”.
Iteration 3 & 4: In the existing list of building blocks (Appian design objects), add a new AI object and adopt the same object lifecycle and behavior pattern.
After evaluating each option’s pros and cons, we concluded that the most natural way is to present AI as a design object just like other elements, e.g. interfaces and decision rules, because low-code developers then don’t have to learn a new structural concept in the platform and they can create, use, and deploy it in the same way they are already familiar with.

Model Configuration
The image above shows major iterations of the AI design object configuration experience.
Iteration 1: Have a navigation panel on the left and let low-code developers go through a multi-step wizard in a dialog.
Iteration 2: Flatten the wizard on the main view to allow low-code developers complete the configuration in more than one sitting.
Iteration 3: Add a navigation bar on the top for potential settings on the object level.
Iteration 4: Simplify steps on the left to only keep document type configuration and document upload. Because we found lots of data analysis and metrics information won’t be available after training completes, and it usually takes a long time to train a model, low-code developers should not be stuck on the last step of a wizard in that case. After they kick off training, they are guided back to a summary screen (See more in the next section.).
To reflect the MVP scope, the top navigation bar is temporarily removed.

Guidance and Validation
Set Up Users for Success
Since our target persona doesn’t have extensive knowledge about data science, in-product guidance and guardrails are critical to ensure they train good models that are usable in production. In ML model training, quality of training data especially has a great impact on training results.
The image above shows major iterations about data validation during model configuration.
Iteration 1: Data validation is a separate step after data is uploaded, but those need to be addressed in the previous step by adjusting data and uploading them again.
Iteration 2: Show actions as buttons inline with warning messages to automatically resolve issues. (Out of the initial scope)
Iteration 3: Show tips and a checklist on the same screen where data is uploaded, so low-code developers can see real-time validations.
Iteration 4: Indicate which documents don’t meet the minimum requirement to make it more clear and easier for low-code developers to fix.

Concept Comprehension and Summary
Iteration 1: A data/document centric approach that separates configuration and training information. However, the left navigation is confusing because it’s hard to know the current status of models right away and what next action is.
Iteration 2: Show model metadata on the top, and training data, training results, and next steps in the body.
Iteration 3: Add a version history view and other settings as tabs. Also add a test pane on the right. However, the information structure is confusing that it’s not clear which model is created most recently and which model is the currently active/published one.
Iteration 4: Show all models on the same view and each model card shows its own information, but the published model is always on the top to make it clear which model is running in an application. On the right pane, show guidance about next steps.

Model Training Results
After a model is trained, a low-code developer needs to evaluate the model by looking at the metrics. Even though a user should carefully take a lot of factors into consideration when reviewing a ML model training result, our goal is to make the information digestible and learnable for low-code developers.
All the iterations shown above take the approach of showing a main model performance indicator at the top level and low-code developers can expand more additional metrics. PMs and I worked closely with ML engineers and UX writers to iterate on UI copies which explain each metric in plain language.
Feedback and User Testing
After I showed initial mockups to ML engineers, they suggested to be very cautious on labeling a model as good or bad based on only one metric because this might mislead low-code developers in their judgement.
We also found in user testing sessions, when users looked at the gauge component showing a big number, they always asked how they could get their model to 100%. However, this should not be their goal because it’s not realistic.
Therefore, in the latest iteration, I removed the gauge visualization and added more instructions about how to leverage various metrics and when which metric is representative.

Implementation and "Make It Happen"
As of August 2022, the team completed the first functional roundtrip. I had a great time working with developers on my team that they took my prototype and interface mockups made in SAIL (Self-Assembling Interface Layer - Appian’s patented front-end framework) and connect with backend APIs seamlessly. They also address my UX review comments on implementation tickets very quickly.
Even though they are based in Spain while other team members, including me, are on the east coast of the U.S and Canada, we figured out our way of working to be collaborative, efficient ,and productive.
During a sprint retrospective session, we gave kudos to one another as usual. The film, Everything Everywhere All At Once, was a big hit at that time, so I took the movie poster and added all team members’ profile pictures in :)